 Nico Brailovsky's thought repository
Nico Brailovsky's thought repositoryPosts for 2010 September
To log or not to log
Post by Nico Brailovsky @ 2010-09-30 | Permalink | Leave a comment
Logging is nice, we all know that. It saves you from having to stay up all night checking when and why your applications fails. It servers to blame the support guys for not reading it. It's useful to stress test your RAID.
But logging where you shouldn't is a pain in the ass waiting to happen.
When designing an application you should choose between domain level objects, wiring objects, library level objects, helper objects, etc. Your logging should be mostly in the wiring of your applications, not in the helper objects and very rarely in the domain level objects. These objects, when well designed, are supposed to be tested and to be run in a production environment with many different loggers. If you log in the middle of your business object you may end up writing logs through cout when you're testing, or worse, when you're supposed to be logging in syslog.
Know where your objects live
Post by Nico Brailovsky @ 2010-09-27 | Permalink | Leave a comment
If you work in an environment where memory management is part of your responsibility then you should be aware of the corner cases in which memory management may come and bite you in the ass. Object ownership is one of those areas.
If you are going to take ownership of an object you need to be very explicit about it. A common (and mostly wrong) pattern is taking ownership of an object, by default. Things work great until you end up with a production coredump after trying to free an invalid pointer.
Foo f1;
Foo f2 = new Foo;
class BadList {
Foo f1, f2;
BadList(Foo f1, Foo *f2) :f1(f1), f2(f2) {}
~BadList(){ delete f1; delete f2; }
}
Seen like that it's more than obvious, but I have seen even experieced programmers fall in this caveat.
Related reading: Oh shit the stack.
Stacktrace or GTFO
Post by Nico Brailovsky @ 2010-09-24 | Permalink | Leave a comment
Remember:

Also, because otherwise this post would be empty:

In reply to this post, Stacktrace or GTFO | 0pointer commented @ 2011-02-21T12:23:56.000+01:00:
[...] NicolasB [...]
Original published here.
Template Metaprogramming XV: Gemini
Post by Nico Brailovsky @ 2010-09-23 | Permalink | Leave a comment
This is the end. My only reader, the end. After 15 chapters of template metaprogramming you should have learned why staying away from them is a good idea, but if you have been following this series then you should know now when and why they could be useful.
These posts were a compendium of mostly isolated data I found during my travels through the depths of metaprogramming tricks, there are books and people much more capable than me if you want to learn more about this subject (Modern C++ Design by Andrei Alexandrescu comes to mind).
The whole idea of having a cache and a virtual template method was nice, but after seeing the result I decided it was best to have a factory method and an IDL. It may not be so l33t, but whoever has to maintain the code after me will be grateful.
This is the last post on this topic because I feel I have written most, if not everything, I can transmit through this medium but also for an important reason, most likely I won't be working with C++ code so much from now on [1] so there won't be as many chances for me to see the dark, insane, side of this beautiful (in its own way) programming language in a programming language. I know most of you must have barely skimmed through these articles, but I still hope you enjoyed them.
[1] That's right, I'm leaving C++ for the dark side of development, I'll be working with Java from now on. Keep in mind this article may have been written a long time before it's published.
[2] Wow, it was a long time since I used the meta-post category
In reply to this post, Manuel commented @ 2010-09-29T17:17:35.000+02:00:
Interfaces FTW !
Original published here.
Redshift: Cool your monitor
Post by Nico Brailovsky @ 2010-09-21 | Permalink | Leave a comment
I've been trying Redshift the last few days. It's a really cool (pun intended) and simple program. It just sits there all day long, doing nothing. Yeap, it's just one more pointless thing on your ps -ef list, up until noon, when it comes to life: it will adjust your monitor's temperature, gradually, from a cool color to a warmer color.
Say what?
I know what you are thinking. "Why the hell did I eat so much cake?". And probably something like "WTF? Monitor temperature? Mine is running cool, k thx bye" too. The monitor temperature (color temperature, to be more accurate) is the percieved temperature of an object emiting light at the specific wavelength of that color:
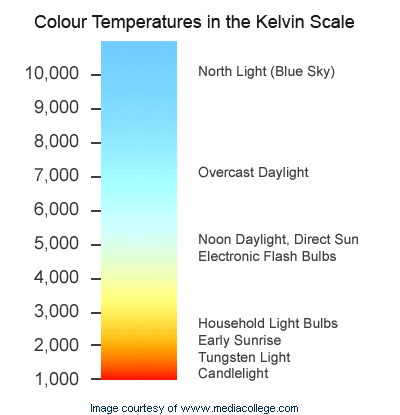 So, a blueish color means a higher temperature, and it's the natural ambience light color you see during the day. Towards the night the color temperature begins too cool down towards a more orange color. This is the temperature Redshift changes.
So, a blueish color means a higher temperature, and it's the natural ambience light color you see during the day. Towards the night the color temperature begins too cool down towards a more orange color. This is the temperature Redshift changes.
So what?
Fair question. After a couple million years our brains got used to seeing a hot color temperature during the day (do I have any reader that old?) so staring at a blue monitor all day will keep you awake all night long, the theory being that switching its temperature towards a reder color will help you sleep at night.
Does it work?
Probably not, but that doesn't make it any less cool (pun not intended). I think if you fine-tune this app to your sleeping hours it may be of some use, because otherwise you'll get a very dark screen at 5pm (don't you people know the timezone in Argentina is FOOBAR'd).
Quote of the week
Post by Nico Brailovsky @ 2010-09-16 | Permalink | Leave a comment
It seems making a compile fail is actually quite easy. That’s what I have most experience with.
From "Template metaprogramming", chapter 10 by me
Template Metaprogramming XIV: Marathon
Post by Nico Brailovsky @ 2010-09-14 | Permalink | Leave a comment
If you remember previous entry, we got our evil device to the point of getting a specific instance using only a type hint. Now we need to put all the code together. I won't add much to the code, you should be able to parse it yourself.
/*******/
struct NIL {
typedef NIL head;
typedef NIL tail;
};
template <class H, class T=NIL> struct LST {
typedef H head;
typedef T tail;
};
/******/
/******/
template <class X, class Y> struct Eq { static const bool result = false; };
template <class X> struct Eq<X, X> { static const bool result = true; };
/******/
/******/
template <class Elm, class LST> struct Position {
private:
typedef typename LST::head H;
typedef typename LST::tail T;
static const bool found = Eq<H, Elm>::result;
public:
static const int result = found? 1 : 1 + Position<Elm, T>::result;
};
template <class Elm> struct Position<Elm, NIL> {
static const int result = 0;
};
/******/
/******/
template <typename LST, int N> struct Nth {
typedef typename LST::Tail Tail;
typedef typename Nth<Tail, N-1>::result result;
};
template <typename LST> struct Nth<LST, 0> {
typedef typename LST::head result;
};
/******/
/******/
template <typename Lst> struct Instances {
typedef typename Lst::head Elm;
Elm instance;
Instances<typename Lst::tail> next;
};
template <> struct Instances<NIL> {};
/******/
/******/
template <int N, typename TypeLst> struct NthInstance {
// This one isnt easy...
// This is the next type in the list
typedef typename TypeLst::tail TypeNext;
// * Nth::result is the Nth type in Lst (i.e. char, int, ...)
typedef typename NthInstance<N-1, TypeNext>::NthInstanceType NthInstanceType;
// * typename Nth::result & is a reference to said type and the ret type
template <typename InstancesLst>
static NthInstanceType& get(InstancesLst &instances_lst) {
return NthInstance<N-1, TypeNext>::get(instances_lst.next);
}
};
// Remember, just for fun we choose a 1-based system (wtf..)
template <typename TypeLst> struct NthInstance<1, TypeLst> {
typedef typename TypeLst::head NthInstanceType;
template <typename InstancesLst>
static NthInstanceType& get(InstancesLst &instances_lst) {
return instances_lst.instance;
}
};
/*********/
class Facade {
typedef LST<int, LST<char, LST<double> > > Lst;
Instances<Lst> instances;
public:
template <typename PK> int find(PK) {
return Position<PK, Lst>::result;
}
template <typename PK>
// This is a difficult one... it should be parsed like this:
// 1) Get the desired instance position using Position::result
// 2) Get the type @ the desired position with NthInstance::Type
// 3) Define said type as a return type (with an & at the end, i.e. make
// it a reference to the return type)
typename NthInstance< Position<PK, Lst>::result, Lst >::NthInstanceType&
get_instance(PK) {
const int idx_position = Position<PK, Lst>::result;
typedef typename NthInstance<idx_position, Lst>::NthInstanceType IdxType;
IdxType &idx = NthInstance<idx_position, Lst>::get( instances );
return idx;
}
};
#include <iostream>
int main() {
Facade f;
int &a = f.get_instance(1);
char &b = f.get_instance('a');
double &c = f.get_instance(1.0);
a = 42; b = 'n'; c = 4.2;
std::cout << f.get_instance(1) << "\n";
std::cout << f.get_instance('a') << "\n";
std::cout << f.get_instance(1.0) << "\n";
a = 43; b = 'm'; c = 5.2;
std::cout << f.get_instance(1) << "\n";
std::cout << f.get_instance('a') << "\n";
std::cout << f.get_instance(1.0) << "\n";
return 0;
}
The only thing missing now is a map, to convert a primitive type to an index type, but that's trivial and so it will be left as an exercise for the reader (?). We just implemented the most evil code in the whole world. Next time, the conclusions.
Sorting by random in bash and mocp random updated
Post by Nico Brailovsky @ 2010-09-09 | Permalink | Leave a comment
Random is nice. And now you can sort by random your output using sort -R. Why would this be useful? Well, I updated my mocp random script with a oneliner:
mocp -c && find -type d | sort -R | head -n1 | awk '{print """$0"""}'; | xargs mocp -a
C++ linking WTF
Post by Nico Brailovsky @ 2010-09-07 | Permalink | Leave a comment
It is a commonly accepted fact that a succesfuly compiled application serves as enough proof of its correctness, but common wisdom doesn't say a thing about linking. If you like linker WTF moments, you'll love this snippet. Can you guess why won't it compile?
struct Foo {
static const int x = 0;
static const int y = 1;
int z(bool x){
return (x)? Foo::x : Foo::y;
}
};
int main() {
Foo z;
std::cout << z.z(true);
return 0;
}
Well, it does compile (gotcha!) but it just won't link. Yet it seems so simple... let's add some more mistery to this WTF moment, try this change:
int z(bool x){
int t = Foo::x;
return (x)? t : Foo::y;
}
Holy shit, now it compiles? WTF? Some more strangeness:
int z(bool){
return (true)? Foo::x : Foo::y;
}
And again, now it compiles. WTF? I'll make a final change, this one should give you a clue about why it won't compile. Revert all changes back to the original code but add this two lines after Foo:
const int Foo::x;
const int Foo::y;
Though weird at first, now you should have a clear picture: * The first case doesn't compiles: x and y are declared in struct Foo, yet the linker doesn't know in which translation unit they should be allocated. * The second and third cases... well I'm not sure why does this compiles but it's probably because the linker can asume in which translation unit x and y should be allocated. I'm to lazy to check. * In the last case we explicitly say where should x and y be. According to standard, this is how these two ints should be declared.
So, some linker strangeness. Beware, it's easy to get trapped by this one.
In reply to this post, Matthew Fioravante commented @ 2015-09-03T22:47:03.000+02:00:
"The second and third cases… well I’m not sure why does this compiles but it’s probably because the linker can asume in which translation unit x and y should be allocated. I’m to lazy to check."
The difference probably has to do with the optimizer. If the optimizer reduces all references to the static variable to a compile time constant then there are no references to the non-existant variable for the linker to complain about.
You can see these kinds of linker bugs happen often in debug builds but not in release builds because of different optimization levels.
Original published here.
Vim Sexual Care
Post by Nico Brailovsky @ 2010-09-02 | Permalink | Leave a comment
Vim bestows its users all sort of magical properties, among which now we can count increased sexual performance. I bet you didn't know, but Vim can help you keep your girl happy for days without end. Don't believe me? Check this page.
