 Nico Brailovsky's thought repository
Nico Brailovsky's thought repositoryPosts for 2013 June
Useless code: a template device to calculate e
Post by Nico Brailovsky @ 2013-06-27 | Permalink | Leave a comment
Recently I needed to flex a bit my template metaprogrammingfooness, so I decided to go back and review and old article I wrote about it (C++11 made some parts of those articles obsolete, but I'm surprised of how well it's aged). To practice a bit I decided to tackle a problem I'm sure no one ever had before: defining a mathematical const on compile time. This is what I ended up with, do you have a better version? Shouldn't be to hard.
template <int N, int D> struct Frak {
static const long Num = N;
static const long Den = D;
};
template <class X, int N> struct MultEscalar {
typedef Frak< N*X::Num, N*X::Den > result;
};
template <class X1, class Y1> struct IgualBase {
typedef typename MultEscalar< X1, Y1::Den >::result X;
typedef typename MultEscalar< Y1, X1::Den >::result Y;
};
template <int X, int Y> struct MCD {
static const long result = MCD<Y, X % Y>::result;
};
template <int X> struct MCD<X, 0> {
static const long result = X;
};
template <class F> struct Simpl {
static const long mcd = MCD<F::Num, F::Den>::result;
typedef Frak< F::Num / mcd, F::Den / mcd > result;
};
template <class X, class Y> struct Suma {
typedef IgualBase<X, Y> B;
static const long Num = B::X::Num + B::Y::Num;
static const long Den = B::Y::Den; // == B::X::Den
typedef typename Simpl< Frak<Num, Den> >::result result;
};
template <int N> struct Fact {
static const long result = N * Fact<N-1>::result;
};
template <> struct Fact<0> {
static const long result = 1;
};
template <int N> struct E {
// e = S(1/n!) = 1/0! + 1/1! + 1/2! + ...
static const long Den = Fact<N>::result;
typedef Frak< 1, Den > term;
typedef typename E<N-1>::result next_term;
typedef typename Suma< term, next_term >::result result;
};
template <> struct E<0> {
typedef Frak<1, 1> result;
};
#include <iostream>
int main() {
typedef E<8>::result X;
std::cout << "e = " << (1.0 * X::Num / X::Den) << "\n";
std::cout << "e = " << X::Num <<"/"<< X::Den << "\n";
return 0;
}
Watchpoints in gdb: wake me up when foo changes
Post by Nico Brailovsky @ 2013-06-25 | Permalink | 2 comments | Leave a comment
I've noticed a lot of people claim gdb is not a good debugger because it doesn't support feature X. X is many times the ability to monitor changes to a memory location (ie when the value of a variable changes). Most times, though, people believe gdb doesn't implement X only because not enough time was spent reading its manual.
In gdb it's very easy to monitor variable changes using watchpoints. Here's a very simple example session:
(gdb) list
1 int main()
2 {
3 int a = 1;
4 int b;
5 a = b;
6 b = 42;
7 return 0;
8 }
Of course we need to be in the proper scope to set a watchpoint:
(gdb) run
Breakpoint 1, main () at test.cpp:3
Let's try to catch when b changes value:
(gdb) watch b
Hardware watchpoint 2: b
Interesting: a hardware watchpoint was set. What might that be?
(gdb) continue
Hardware watchpoint 2: b
Old value = 0
New value = 42
main () at test.cpp:7
Nice! gdb alerted us of the value change by breaking program execution. This can come in handy to fix race conditions.
Hardware and software watchpoints
Gdb will use hardware watchpoints if the underlying platform provides them; that means your architecture should provide some kind of hook for gdb to be alerted when a memory write at a certain address occurs. Hardware watchpoints are quite easy to use, relatively speaking, but not all platforms support them. In that case gdb will use software watchpoints, which are quite expensive and slow. Did you ever try to run a program by pressing "step" continuously? Well, a software watchpoint is similar, gdb will have to execute a program step by step and check if the value has changed in between steps.
As usual, gdb's manual has a lot more info.
PS: Once you find your bug with the aid of a watchpoint, please go and read some books about encapsulation!
Detecting and ignoring third party memory problems with Valgrind
Post by Nico Brailovsky @ 2013-06-20 | Permalink | Leave a comment
Lot's of people seem to give up on Valgrind after they see the dreaded "More than ### errors detected, go and fix your program". If the bulk of these errors are caused by crappy code in third party libraries there's very little to be done to fix them, other than creating a ticket for the library maintainer (and if the bulk of these errors are caused by your own code... well, don't write a watchdog please, do fix your program!). And that's assuming the reported error is not even a false positive, since Valgrind can report problems for crazy optimizations -O3 might have or for weird operator arithmetic.
If these spurious memory errors are there for too long most people will start ignoring Valgrind's output. Luckily, ignoring errors we can't fix is a possibility too, using Valgrind's ignore files.
- Check if someone else has already found this issue. Many times libraries do have an "official" ignore file for the lib
- If you find no ignore file, make really really sure the problem is not on your code. Preferably write a minimal unit test that triggers the warning on Valgrind. Make sure you're not misusing the library.
- Add whatever warnings you found which were not on your application to a new ignore file
- Share your ignore file with the world! Other people will either find it useful or tell you that what you thought was a bug on a lib is actually a problem on your code. That happens more often than not.
C++ exceptions under the hood appendix II: metaclasses and RTTI on C++
Post by Nico Brailovsky @ 2013-06-13 | Permalink | Leave a comment
A long time ago, when we where just starting to write our mini ABI to handle exceptions without libstdc++'s help, we had to add an empty class to appease the linker:
namespace __cxxabiv1 {
struct __class_type_info {
virtual void foo() {}
} ti;
}
I mentioned this class is used to check whether a catch can handle a subtype of the exception thrown, but what does that exactly mean? Let's change a bit our throwing functions to see what happens when we start dealing with inheritance. You may want to check the source code for these examples.
struct Derived_Exception : public Exception {};
void raise() {
throw Derived_Exception();
}
void catchit() {
try {
raise();
} catch(Exception&) {
printf("Caught an Exception!\n");
} catch(Derived_Exception&) {
printf("Caught a Derived_Exception!\n");
}
printf("catchit handled the exception\n");
}
What should happen in this example is crystal clear: it should print "Caught an Exception", because that catch block should be able to handle both types, Exception and Derived_Exception. Not only that, if we compile throw.cpp we'll get a warning to let us know that the second catch is dead code:
throw.cpp: In function void catchit():
throw.cpp:15:7: warning: exception of type Derived_Exception will be caught [enabled by default]
throw.cpp:13:7: warning: by earlier handler for Exception [enabled by default]
Luckily a warning won't stop compilation; we can continue and try to link the resulting .o; we'll find a linker error:
throw.o:(.rodata._ZTI17Derived_Exception[typeinfo for Derived_Exception]+0x0): undefined reference to `vtable for __cxxabiv1::__si_class_type_info'
And again we start seeing __type_info errors. If we create a fake __si_class_type_info to workaround this problem we we'll finally see our ABI breaks down when dealing with inheritance, in a rather funny way: the compiler will warn us about dead code and then we see that same code being executed by our ABI!
g++ -c -o throw.o -O0 -ggdb throw.cpp
throw.cpp: In function void catchit():
throw.cpp:15:7: warning: exception of type Derived_Exception will be caught [enabled by default]
throw.cpp:13:7: warning: by earlier handler for Exception [enabled by default]
gcc main.o throw.o mycppabi.o -O0 -ggdb -o app
./app
begin FTW
Caught a Derived_Exception!
end FTW
catchit handled the exception
Clearly there's something wrong with our ABI, and it's very easy to trace this problem back to the definition of "can_handle", the part of the code that checks whether an exception can by caught by a catch block:
bool can_handle(const std::type_info thrown_exception,
const std::type_info catch_type)
{
// If the catch has no type specifier we;re dealing with a catch(...)
// and we can handle this exception regardless of what it is
if (not catch_type) return true;
// Naive type comparisson: only check if the type name is the same
// This won't work with any kind of inheritance
if (thrown_exception->name() == catch_type->name())
return true;
// If types don't match just don't handle the exception
return false;
}
Our ABI gets the std::type_info for the exception being thrown and for the type which can be handled, and then compares if the names for these types is the same. This is fine as long as no inheritance is involved, but in the example above we already found a case where an exception should be handled even though a name is not shared.
The same problem will arise when trying to catch a pointer to an exception: the names won't match. Even more interesting, if you try and link throw.cpp but change the catch to receive a pointer instead, you'll get a new linker error. If you fix it you should end up with something like this:
namespace __cxxabiv1 {
struct __class_type_info { virtual void foo() {} } ti;
struct __si_class_type_info { virtual void foo() {} } si;
struct __pointer_type_info { virtual void foo() {} } ptr;
}
A very interesting pattern is starting to emerge: there is a different *_type_info for each possible catch type used. In fact the compiler will generate a different structure for each throw style. For example, for these throws:
throw new Exception;
throw Exception;
the compiler would generate something like:
__cxa_throw(_Struct_Type_Info__Ptr__Exception);
__cxa_throw(_Struct_Type_Info__Class__Exception);
In fact, even for this simple example, the inheritance web (not tree, web) is quite complex (note that I'm kind of inventing the mangling here, it's not what gcc uses):
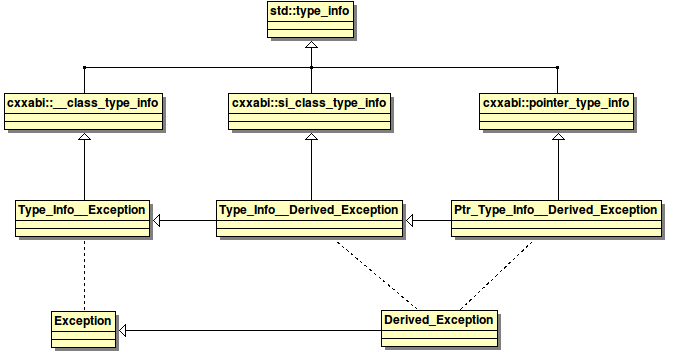
All these classes are generated by the compiler to specify precisely which type is being thrown, and how. For example, if an exception of type "Ptr__Type_Info__Derived_Exception" is thrown then a catch can handle it if:
The catch type equals the thrown type exactly (this is the only check our ABI does).If the catch type is a pointer (ie inherits from cxxabi::ponter_type_info), and said pointer can be casted to the exception type.If the thrown type is a derived type, then we need to check if the catch type is a parent type
And this list is still missing lots of possibilities, but for the full list is better to check a real C++ ABI. LLVM has very clear and easy to understand ABI, you can check these details in the file "private_typeinfo.cpp". If you check LLVM's implementation of run time type information, you'll soon realize why we didn't implement this on our ABI: the amount of rules to determine whether two types are the same or not is incredibly complex.
C++ exceptions under the hood appendix I: the true cost of an exception
Post by Nico Brailovsky @ 2013-06-11 | Permalink | 2 comments | Leave a comment
Remember a long way back, when the series on exception handling was just started, that I mentioned these articles would only apply for gcc/x86? There is a reason for that since not all compilers implement exception handling the same way. In particular, there are two major ways of doing it:
- With a lookup table and some metadata, like the Itanium ABI specifies; this is what we talked about.
- Sj/Lj (ARM): Registering exception handling information upon entering or exiting a method.
The way gcc (and many other compilers) implement this ABI on x86 is by using metadata (the .gcc_except_table and the CFI). Although it's rather difficult to parse, and it might take a long time to parse this on runtime when an exception is thrown, it has a great upside: if no exceptions are thrown then there's no setup cost to be paid. This is called "Zero-cost exception handling" because a normal execution, where no exceptions are thrown, no penalty is payed. The performance is exactly the same we would have as if we had specified nothrow. That's right, leaving code locality & caching issues aside, using exceptions or not has no performance penalty unless an exception is actually thrown. This is a great advantage and it goes in line with C++ philosophy of having no-cost for non used features.
When using the noexcept specification while declaring a method (or an empty throw specifier, pre C++11) in the setup used for these articles the compiler would omit the creation of the .gcc_except_table. This will make the code more compact and it will improve the cache usage, but it's very unlikely that will have a noticeable impact on the performance of the application.
If we talk about ARM, Sj/Lj seems to be the default option (I'm sure there's a good reason for that but I don't have enough experience with ARM to know it). This exception handling method is based on registering exception handling information upon entering or exiting a method which either uses exceptions or requires a cleanup if an exception is thrown. This will result in a quicker exception handling, but the setup cost is payed whether an exception is thrown or not.
If you're interested on reading more about sjlj and zero cost exception handling LLVM has great documentation.
Bash scripting and getops
Post by Nico Brailovsky @ 2013-06-06 | Permalink | Leave a comment
Did you ever write a bash script and thought it looked too clean? Yeah, me neither. Anyway, now you can make it look even worse by using getopt. As an upside, you'll be able to read command line options from a user without having to resort to nasty hacks, like hardcoding the switch position into the argv.
getopt should be installed by default in most Linux distros, and you can even run it as a command line program. It's quite easy to use on a bashcript. For example, something like:
while getopts "bar" opt; do
case "$opt" in
b) echo "Option b is set"
;;
a) echo "Option a is set"
;;
r) echo "Option r is set"
;;
esac
done
It won't look pretty but it does get the job done. According to "man getopt" it supports things like short & long options and defaults; if you need something more complex, you should probably be using a proper language instead of a bash script.
C++ exceptions under the hood 21: a summary and some final thoughts
Post by Nico Brailovsky @ 2013-06-04 | Permalink | Leave a comment
After writing twenty some articles about C++ low level exception handling, it's time for a recap and some final thoughts. What did we learn, how is an exception thrown and how is it caught?
Leaving aside the ugly details of reading the .gcc_except_table, which were probably the biggest part of these articles, we could summarize the whole process like this:
- The C++ compiler actually does rather little to handle an exception, most of the magic actually happens in libstdc++.
- There are a few things the compiler does, though. Namely:
- It creates the CFI information to unwind the stack.
- It creates something called .gcc_except_table with information about landing pads (try/catch blocks). Kind of like reflexion info.
- When we write a throw statement, the compiler will translate it into a pair of calls into libstdc++ functions that allocate the exception and then start the stack unwinding process by calling libstdc.
- When an exception is thrown at runtime __cxa_throw will be called, which will delegate the stack unwinding to libstdc.
- As the unwinder goes through the stack it will call a special function provided by libstdc++ (called personality routine) that checks for each function in the stack which exceptions can be caught.
- If no matching catch is found for the exception, std::terminate is called.
- If a matching catch is found, the unwinder now starts again on the top of the stack.
- As the unwinder goes through the stack a second time it will ask the personality routine to perform a cleanup for this method.
- The personality routine will check the .gcc_except_table for the current method. If there are any cleanup actions to be run, it will "jump" into the current stack frame and run the cleanup code. This will run the destructor for each object allocated at the current scope.
- Once the unwinder reaches the frame in the stack that can handle the exception it will jump into the proper catch statement.
- Upon finishing the execution of the catch statement, a cleanup function will be called to release the memory held for the exception.
Having learned how exceptions work we are now in a position to better answer why it's hard to write exception safe code.
Exceptions, while conceptually clean, are pretty much "spooky action at a distance". Throwing and catching an exception involves a certain degree of reflexion (in the sense that a program must analyze itself) which is not common for C++ applications.
Even if we talk about higher level languages, throwing an exception means we cannot rely on our understanding of how a normal program execution flow should work anymore: we are used to a pretty much linear execution flow with some conditional operators branching or calling other functions. With an exception, this no longer holds true: an entity which is not the code of our application is in control of the execution, and it goes around the program executing certain blocks of code here and there without following any of the normal rules. The instruction pointer gets changed by each landing pad, the stack is unwinded in ways we can't control and, ultimately, a lot of magic happens under the hood.
To summarize it even more: exceptions are hard simply because they break the natural flow of a program as we understand it. This does not mean they are intrinsically bad as properly used exceptions can surely lead to cleaner code, but they should always be used with care.