 Nico Brailovsky's thought repository
Nico Brailovsky's thought repositoryPosts for 2012 November
Cool C++0X features XIII: auto and ranged for, cleaner loops FTW
Post by Nico Brailovsky @ 2012-11-29 | Permalink | Leave a comment
Long time without updating this series. Last time we saw how the ugly
for (FooContainer::const_iterator i = foobar.begin(); i != foobar.end(); ++i)
could be transformed into the much cleaner
for (auto i = foobar.begin(); i != foobar.end(); ++i)
Yet we are not done, we can clean that a lot more using for range statements.
Ranged for is basically syntactic sugar (no flamewar intended) for shorter for statements. It's nothing new and it's been part of many languages for many years already, so there will be no lores about the greatness of C++ innovations (flamewar intended), but it still is a nice improvement to have, considering how tedious can be to write nested loops. This certainly looks much cleaner:
for (auto x : foobar)
This last for-statement, even though it looks good enough to print and hang in a wall, raises a lot of questions. What's the type of x? What if I want to change its value? Let's try to answer that.
The type of the iterator will be the same as the type of the vector, so in this case x would be an int:
std::vector foobar;
for (auto x : foobar) {
std::cout << (x+2);
}
And now, what happens if you want to alter the contents of a list and not only display them? That's easy too, just declare x as an auto reference:
std::vector foobar;
for (auto& x : foobar) {
std::cout << (x+2);
}
This looks really nice but it won't really do anything, for two different reasons:
- Ranged fors won't work until g++ 4.5.6 is released
- The list is empty!
There are many ways to initialize that list, but we'll see how C++0X let's you do it in a new way the next time.
Hugging borked on Ubuntu?
Post by Nico Brailovsky @ 2012-11-27 | Permalink | Leave a comment
Hugging is pretty awesome to create panoramic photos. I use it regularly, for example for this awesome Prague old town square panoramic I took some time ago:

At some point I realized that, after an upgrade, Hugging just stopped finding connection points. Apparently there's a licences issue somewhere. Just "sudo apt-get install autopano-sift" and continue hugging.
Vim tip: goto column
Post by Nico Brailovsky @ 2012-11-22 | Permalink | Leave a comment
You can quickly jump to a specified column in Vim by simply typing the column number followed by a pipe, like this:
80| # go to the 80th column
False sharing in multi threaded applications, part II
Post by Nico Brailovsky @ 2012-11-20 | Permalink | Leave a comment
In the last entry we learned how an apparently parallel algorithm can turn into a sequential nightmare via false sharing; what you may think to be two independent variables may actually be spatially close, thus sharing a cache line which gets invalidated by each and every write across cores. But is this a real world issue? If so, how can we fix it?
We'll work backwards: let's see first how can this be fixed, and then we'll check if this is actually a real world issue.
Remember our code sample, from last time:
void lots_of_sums(unsigned idx, int v[])
{
const unsigned itrs = 200010001000;
for (int i=0; i < itrs; ++i)
v[idx].num = i;
}
An easy way to avoid false sharing would be to just assign i to a temporary variable, then assign the real result to v[i]; this way, you would be writing only once, the intermediate results will be in TSS, thus avoiding the contention in the loop.
The second strategy to solve this problem would be to use padding. Knowing that your cache line is made of 64 bytes will let you write something like this:
struct Padded {
int num;
char pad[60];
};
Of course, this has another problem: what about the offset? We need not only padding but also spacing, for the alignment.
struct Padded {
char space[60];
int num;
char pad[60];
};
Alternatively, you could use the align keyword of C++0x, but since it's not implemented on g++ I have never tested it before, so I have no idea how it's supposed to work. For more information on this you can check Herb Sutter's article, Eliminate False Sharing.
False sharing in multi threaded applications
Post by Nico Brailovsky @ 2012-11-19 | Permalink | Leave a comment
Concurrent programing is hard. Very hard. But every once in a while you can actually find a textbook problem, an application for which a parallel algorithm is not only simple but also intuitive, so clear that it would be difficult to actually do it any other way. You put on your high speed helmet and fasten your seatbelt, ready for an FTL (faster than lineal) jump.
Running make && make test only show lower numbers. You actually decreased the performance of your application, by making it multi-threaded! How can this be possible?
While writing concurrent algorithms there are many places where you can fail, miserably. Contention is only one of them, but this is a very subtle way of failure; it will render your concurrent algorithms into a very complicated sequential algorithm, run in many cores. How can a simple concurrent algorithm turn into such a mess?
In many cases, false sharing is the culprit of the lost performance. How exactly? Let's write a simple example for this:
void lots_of_sums(unsigned idx, int v[])
{
const unsigned itrs = LOTS;
for (int i=0; i < itrs; ++i)
v[idx].num = i;
}
Imagine this function, one running in each core and v defined as a simple array. We can expect this to have a linear scalability, right? Turns out it's not that simple. Why? Let's see how v is laid out in memory:
+------------+--+--+--+------+-----------------+
|Random stuff|V0|V1|V2|...|VN|More random stuff|
+------------+--+--+--+------+-----------------+
So, v will (most likely) be made of adjacent chunks in memory. We can also assume that sizeof(v[i]) will be 4 or 8 bytes, or something small like that. Why is that important?
Remember that nowadays a CPU core is amazingly fast, so much that they make main memory look like dial up. To avoid waiting for the main memory to complete a request, several levels of cache exists. These caches know nothing about your application (well, mostly) so they can't know that v0 and v1 are actually different variables. Notice how this would apply if instead of a vector they were two random variables which happen to be allocated spatially close.
If the CPU cache, L1 for the friends, can't know that v0 and v1 are separate, it will probably try to cache a whole chunk of memory. Say, maybe 64 or 128 bytes. Why should you care?
Let's go back to our code. When you see this
...
v[idx].num = i;
...
you just see independent accesses to different variables. What will the cache see? Let's go back to our memory layout, but this time let's make up an offset too:
0xF00 0xF10 0xF14... 0xF40
+------------+--+--+--+------+-----------------+
|Random stuff|V0|V1|V2|...|VN|More random stuff|
+------------+--+--+--+------+-----------------+
So, if we assume a 64 byte cache line, then how might the CPU see a read-write process for v[0]? Something like this, probably:
+---------+-------------------+----------------------------+---------------------------+
| C Code | CPU | L1 | Main Memory |
|---------|-------------------|----------------------------|---------------------------|
| | | | |
|Read v[0]| | | |
| +------+| | | |
| +-> Hey, get me 0xF10 | | |
| | +----------------+| | |
| | +> Huh... I don't have 0xF10, | |
| | | let me get that for you... | |
| | | +-----------------------+ | |
| | | +-> 0xF00... yup, here you go |
| | | | |
| | | I have it now! | |
+---------+-------------------+----------------------------+---------------------------+
Note an important bit there: the CPU requested 0xF10 but L1 cached the whole segment, from 0xF00 to 0xF40. Why is that? It's called spatial locality or locality of reference and since it's not the main goal of this article I'll just say that L1 will cache the whole segment just in case you want it.
So far so good. What happens when you add more CPUs and write OPs? Remember that write OPs are cached as well.
Looks pretty similar, but note an interesting thing: CPU1 will read v[0], which translates to 0xF10, whereas CPU2 will read v[1], which translates to 0xF14. Even though these are different addresses, they both correspond to 0xF00 segment, thus L1 will have actually read the same chunk of memory!
The problem with this starts when a thread needs to write. Like this:
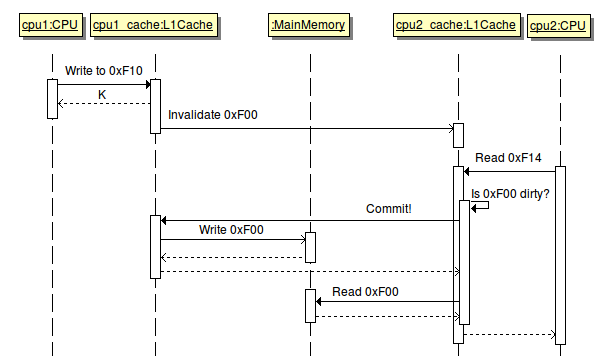 Wow, a simple read from L1 cache now fails because it's been marked as dirty by an L1 from another CPU. How crazy is that? (*)
Wow, a simple read from L1 cache now fails because it's been marked as dirty by an L1 from another CPU. How crazy is that? (*)
Can you see now why our simple and elegant parallel algorithm has turned into a messy lineal... steaming pile of code? Each time a core tries to write to his own variable, it's inadvertently invalidating the variables other cores need. This is called false sharing, and we'll see a fix next time.
(*) Disclaimer: this diagram, and the ones before, are simplifications of what actually happens. In reality there are several levels of cache, and some of those may be shared between cores, so most likely the L1 won't need to go to main memory. Also, even in the case where there is no shared cache between cores, there are cache coherency protocols which will most likely avoid a read from main memory.
Easy bind dns log analyzer
Post by Nico Brailovsky @ 2012-11-13 | Permalink | 7 comments | Leave a comment
Any real-programmer (tm) should be able to memorize all the static IPs in his network and should feel more comfortable using the IP to access the LAN resources, instead of those user friendly URL things. Of course, not everyone is a real-programmer (tm), and these people usually drive crazy the poor guys who do remember all the static IPs in the office. For them, the DNS was invented.
Some time ago I set up a bind9 on a spare server I had. Easy job, a side project of a boring late night. Of course, there was no point in just setting up my own TLD; I now had the power to have fun with DNS poisoning, and I could also create nice reports of the queries to the DNS server.
Having fun with a DNS might be the topic for another post, for this one I'll just focus on how to get query statistics from a bind server.
After grepping the web a little bit, I found a rather disconcerting lack of bind log analyzers. I just wanted a list of the most popular queries, as well as the ability to group the log by it's IP (and may be even to get the computer's SMB name). Couldn't have asked for a better chance to flex a little bit my Ruby-foo, and here is the hackish result for whoever may want to do something similar:
#!/usr/bin/ruby1.8
class Hits
def initialize(n,v,k=nil)
@n=n
@v=v
@k=k
end
def n() @n; end
def v() @v; end
def k() @k; end
def <(o) @n < o.n; end
end
if ARGV.length == 0 then
puts "Usage: dns.rb DNS_LOG [--domains] [--ip [--no-samba]]"
puts " --domains will list all queried domains"
puts " --ip will list every query gruoped by IP"
exit
end
@domains = @ip = @nosamba = false
ARGV.each { |arg|
case arg
when '--domains' then @domains = true
when '--ip' then @ip = true
when '--no-samba' then @nosamba = true
end
}
fp = File.open ARGV[0]
queries_by_ip = {}
queries_by_domain = {}
fp.each_line { |l|
v = l.split(' ')
if not (v.nil? or v.length < 4) then
ip = v[1].split('#')[0]
query = v[3]
if queries_by_domain[query].nil? then queries_by_domain[query] = 0 end
queries_by_domain[query] += 1
if queries_by_ip[ip].nil? then queries_by_ip[ip] = [] end
queries_by_ip[ip].push query
end
}
if @domains then
hits = []
queries_by_domain.each { |k,v|
hits.push Hits.new(v, k)
}
hits.sort!.reverse!.each { |h|
puts h.v + " has " + h.n.to_s + " hits"
}
end
if @ip then
lst = []
queries_by_ip.each { |ip,queries|
lst.push Hits.new(queries.length, ip, queries)
}
lst.sort!.reverse!.each { |h|
puts "Report for " + h.v + ", Samba addr:"
if not @nosamba then Kernel.system "nmblookup -A " + h.v end
puts "Requested " + h.n.to_s + " URLs:"
h.k.uniq.each { |url|
puts "t" + url
}
puts "."
puts "."
}
end
Redirecting connections from one port to another with iptables
Post by Nico Brailovsky @ 2012-11-06 | Permalink | Leave a comment
People say iptables are incredibly useful. Mind you, I have gotten mostly headaches out of it, but it is easy to see they are a powerful tool. The other day (for reasons not relevant to this post) I needed to run a service on a port, yet have it accept connections in a different port. Say, the service should be listening on port 1234, but the server should accept any connection on port 4321 and "redirect" each package to the correct port. Turns out iptables is the tool for the job.
For the impatient ones, this is the command I used:
iptables -t nat -A PREROUTING -s 192.168.10.0/24 \
-p tcp --dport 4321 -j DNAT --to :1234
Let's analyze this part by part. First I tried something like this:
# Caution: This is wrong and won't work!
iptables -A INPUT -s 192.168.1.0/24 --dport 4321 --to :1234
Seems clear enough: * -A INPUT will add this rule to the INPUT chain (i.e. the list of rules that are run for every incoming packet. * -s 192.168.1.0/24 will filter the packages, so this rule will only be applied to the packets incoming from the 192.168.1.0/24 network. * --dport 4321 will filter the packages again, so we can apply this rule not only to those packets incoming from the LAN but also to those packet to port 4321. * --to :1234 is the rule to rewrite the destination port.
Too bad this won't work. To begin with, the --dport option will fail, since it makes no sense to talk about ports without specifying a protocol (i.e. ports are a TCP layer concept, not an IP layer conecpt, so iptables doesn't know what to do with a --dport option!). Thus, let's rewrite our command like this:
# Caution: This is wrong and won't work!
iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 4321 --to :1234
Now iptables will complain about the --to option. This is because iptables can't rewrite a package (i.e. use the --to option) unless you specify to jump to the DNAT table (?). Now our command should look like this:
# Caution: This is wrong and won't work!
iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 4321 -j DNAT --to :1234
iptables will still complain: you can't use DNAT unless you use a nat table, so we have to add -t nat. If we do that, iptables will complain once more about not being able to use DNAT in the INPUT chain, it is only available in the PREROUTING/OUTPUT chains. This is related to the order in which iptables processes its rules.
With all this in mind, we can now write a command that will run:
iptables -t nat -A PREROUTING -s 192.168.10.0/24
-p tcp --dport 4321 -j DNAT --to :1234
stlfilt: read ugly tmpl errors
Post by Nico Brailovsky @ 2012-11-01 | Permalink | Leave a comment
There's nothing better for Monday mornings than the smell of hundreds of template errors after a make clean all. When using template metaprogramming, a tiny misplaced coma can generate enough error code that, if printed, would crush you under tones of paper. And don't even try to read them, it'll make your head explode.
Luckily STLFilt can be quite a relief when dealing with this kind of errors. Granted, it won't make a steaming pile of poo seem to be a nice poem, but if you have something like the dog in the picture, to use a metaphor, at least it would put a blanket on its face.